バラバラにして組み立てて - Normalizer
Unicode の正規化
Unicode にはいろいろと特徴があるのですが、その中の 1 つに正規化というものがあります。
これを理解するにはまず互換文字と、正規等価と互換等価を理解しなくてはいけないわけですが、私もよく分かっていません ^^;; Impress の Internet Watch の連載記事「文字の海、ビットの舟」の特別編 24, 25 や貞廣氏の「使いこなそうユニコード」の「Unicode 正規化とは」などをご覧ください。
あっ、原典にあたりたい人には Unicode Standard Annex #15: Unicode Normalization Forms をご覧ください。
で、簡単にいえば「が」を「か」+「゛」としてあつかえるということらしいです。この場合は本当に等しいかどうかといわれれば等しくないわけですね。
で、文字としてちゃんと等しい場合を正規等価、前述の例のような場合を互換等価といいます。
問題は互換等価とはいうものの、プログラム的には等価として扱う必要があるということです。
そこで、登場するのが正規化です。互換等価のものを変換して、プログラム的に等価として扱えるようにしましょうということらしいです。その変換の方式を正規化形式というわけです。
正規化形式には
- Normalize Function Composite (NFC)
- Normalize Function Decomposite (NFD)
- Normalize Function Compativle Composite (NFKC)
- Normalize Function Compativle Decomposite (NFKD)
の 4 種類があります。Compativle なのに省略したときに K なのは Composite と区別がつかなくなるかららしいです。
Composite が文字の合成、Decomposte が文字の分解です。「か」+「゛」を「が」にするのが合成で、逆が分解ですね。
ちなみに、ここで書いている「゛」は結合文字用の濁点とは違うコードが割り当てられています。「゛」が U+309b で結合文字用の濁点は U+3099 です。複雑ですね〜。
さて、Java でははじめから Unicode が使えたわけですが、正規化には対応していませんでした。やっと、Java SE 6 から正規化をサポートするようになったわけです。
どうやって使えばいいのか、試してみましょう。
とりあえず、正規化
正規化をおこなうクラスは java.text.Normalizer クラスです。
このクラスにはたった 2 つのメソッドしか定義されていません。それも、2 つとも static なメソッドなので使うのは簡単そうです。
| サンプルのソースコード | NormalizerSample1.java |
|---|
正規化をおこなうメソッドは Normalizer.normalize メソッドです。このメソッドでは正規化した後に Unicode の値がどのようになるか表示させています。
サンプルはちょっと長いので、実際に変換している部分だけを以下に示します。
private static final String gagi1 = "がぎぐげご";
private static final String gagi2 = new String(new char[]{'\u304b', '\u3099',
'\u304d', '\u3099',
'\u304f', '\u3099',
'\u3051', '\u3099',
'\u3053', '\u3099'});
public NormalizerSample1() {
JFrame frame = new JFrame();
JPanel panel = new JPanel();
GridBagLayout layout = new GridBagLayout();
constraints.anchor = GridBagConstraints.WEST;
constraints.weightx = 1.0;
constraints.weighty = 1.0;
constraints.ipadx = 10;
constraints.ipady = 5;
panel.setLayout(layout);
showString(panel, layout, "NFC:", Normalizer.normalize(gagi2, Normalizer.Form.NFC));
showString(panel, layout, "NFD:", Normalizer.normalize(gagi1, Normalizer.Form.NFD));
showString(panel, layout, "NFKC:", Normalizer.normalize(gagi2, Normalizer.Form.NFKC));
showString(panel, layout, "NFKD:", Normalizer.normalize(gagi1, Normalizer.Form.NFKD));
frame.add(panel);
frame.pack();
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setVisible(true);
}
GUI に関するコードが入ってしまって見づらいかもしれませんが、赤字のところが正規化をおこなっているところです。
normalizer メソッドの第 1 引数は文字列 (正確には CharSequence インタフェース)、第 2 引数が正規化の形式になります。正規化の形式は enum の Normalizer.Form であらわされています。
これを実行してみたのが、下図です。
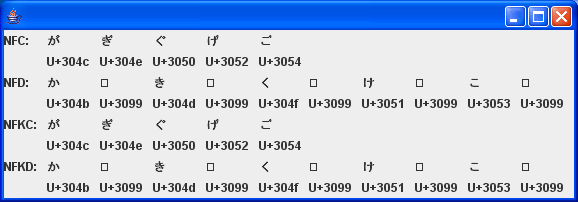
濁点の部分が豆腐になっていますが、それはフォントがないせいです。
というわけで、ちゃんと文字を合成、分解できることが分かりました。
文字を比較する
正規化できるとなったら、後はそれが等しいかどうかを比較しなければいけません。
| サンプルのソースコード | NormalizerSample2.java |
|---|
同じ形式を用いて正規化した後に比較をおこなってみましょう。
import java.text.Normalizer;
public class NormalizerSample2 {
private static final String gagi1 = "がぎぐげご";
private static final String gagi2 = new String(new char[]{'\u304b', '\u3099',
'\u304d', '\u3099',
'\u304f', '\u3099',
'\u3051', '\u3099',
'\u3053', '\u3099'});
public NormalizerSample2() {
System.out.println("gagi1 == gagi2: " + gagi1.equals(gagi2));
String gagi1nfc = Normalizer.normalize(gagi1, Normalizer.Form.NFC);
String gagi2nfc = Normalizer.normalize(gagi2, Normalizer.Form.NFC);
System.out.println("gagi1 -> NFC == gagi2 -> NFC: " + gagi1nfc.equals(gagi2nfc));
String gagi1nfd = Normalizer.normalize(gagi1, Normalizer.Form.NFD);
String gagi2nfd = Normalizer.normalize(gagi2, Normalizer.Form.NFD);
System.out.println("gagi1 -> NFD == gagi2 -> NFD: " + gagi1nfd.equals(gagi2nfd));
String gagi1nfkc = Normalizer.normalize(gagi1, Normalizer.Form.NFKC);
String gagi2nfkc = Normalizer.normalize(gagi2, Normalizer.Form.NFKC);
System.out.println("gagi1 -> NFKC == gagi2 -> NFKC: " + gagi1nfkc.equals(gagi2nfkc));
String gagi1nfkd = Normalizer.normalize(gagi1, Normalizer.Form.NFKD);
String gagi2nfkd = Normalizer.normalize(gagi2, Normalizer.Form.NFKD);
System.out.println("gagi1 -> NFKD == gagi2 -> NFKD: " + gagi1nfkd.equals(gagi2nfkd));
}
public static void main(String[] args) {
new NormalizerSample2();
}
}
これを実行してみるとどうなるでしょうか。
C:\temp>java NormalizerSample2 gagi1 == gagi2: false gagi1 -> NFC == gagi2 -> NFC: true gagi1 -> NFD == gagi2 -> NFD: true gagi1 -> NFKC == gagi2 -> NFKC: true gagi1 -> NFKD == gagi2 -> NFKD: true C:\temp>
一番はじめの比較は flase になっています。これはこの 2 つの文字列が正規等価でないことを示しています。
その後の比較はすべて互換等価かどうかを調べるものです。
これからは、文字列の比較はここで行ったように文字を正規化した後に比較するということが必要になるのかもしれません。
おわりに
Unicode の正規化はなかなか難しいのですが、今後はこういうことも考えなくてはいけなくなってきそうです。
ただ、すべての文字を NFC なり NFD で変換してしまえばいいかというと、それはそれで問題のようです。オリジナルは残しておかなくては、互換文字を使っているという情報がなくなってしまいます。
比較のときだけオリジナルはそのままにして、正規化をおこなうのがいいのでしょう。そういう意味でも Normalizer はオリジナルとは別に文字列を作成してくれるので、この用途にぴったりです。
参考
- The Unicode Standard Annex #15: Unicode Normalization Forms
- 小形克宏 「文字の海、ビットの舟」 特別編24, 25 「改正JIS X0213 と Unicode の等価属性/正規化について」(上)(下)
- 貞廣知行 「使いこなそうユニコード」 「Unicode 正規化とは」
(Nov. 2005)