|
|
New I/O Buffer |
||
|
配列とはちょっと違う |
||
|
New I/O の一番手は Buffer です。 Buffer は boolean を除いたプリミティブに特化したコンテナクラスです。ただし、List や Vector などとは異なり、サイズを変更することはできません。 と、聞くと、「なんだ配列と変わらないじゃないか」と思いませんか。逆に、オブジェクトを扱えない分、配列より劣っているような感じも受けます。 でも、実際にはそんなことはなくて、いろいろと使える場面もあると思います。Buffer の主な特徴は
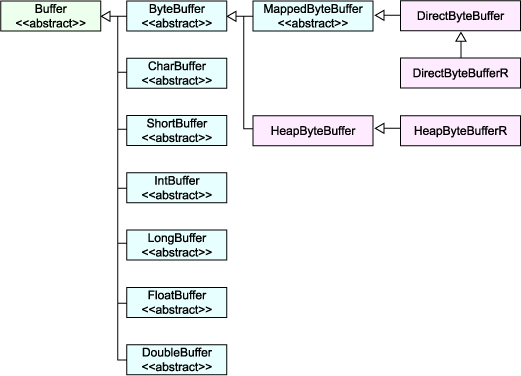
などがあります。 Buffer オブジェクトにアクセスするときには基本的にシーケンシャルアクセスなので (ランダムアクセスでも使用可能ですが)、ArrayList クラスなどに比較すると高速にアクセスを行うことができます。ただし、読み込み/書き込みを行っている地点を変更するためにさまざまなメソッドが用意されており、必ずしも一度終わりまでアクセスしたらそこでおしまいというわけではありません。 Buffer クラスはプリミティブに特化しているので、例えば get メソッドなどの戻り値を Object にして、派生クラスはこれをオーバライドすることができません。したがって、Buffer クラスには get メソッドなどは定義されていません。get メソッドは派生クラスで扱うプリミティブ専用に定義されます。 これは逆にいえば、プリミティブの型の数だけ Buffer の派生クラスがあることになります。ただし、Buffer クラスでは get メソッドなどは定義されていなくても、すべての派生クラスでアクセスの方法を統一しています。このため、1 つのクラスの使い方が分かれば、他の派生クラスも同じように使用することができます。 最後の 2 つの特徴が特に New I/O での売りになる特徴になると筆者は考えています。特にヒープ外のメモリアクセスは今までは JNI を使用して行うしかなかったので、大きな特徴になると思います。これで、大きなデータでも高速に効率よくアクセスすることが可能になります。ただし、ヒープ外なので取り扱いには注意する必要があると思いますが。 ファイルをメモリにマップするということは、例えばファイルのある部分が頻繁にアクセスされていた場合、その部分をメモリに読み込んでしまってそれに対してアクセスするようにすることです。いわゆる、ファイルのメモリキャッシュですね。 このようにメモリにマップされたファイルをアクセスするための専用の Buffer クラスの派生クラスが用意されているので、通常のファイルアクセスより高速にアクセスを行うことができます。 このように見ていくと、やはり Buffer クラスは Channel などと組み合わせることで大規模なデータを効率よくアクセスするためにデザインされているようです。 さて、Buffer クラスの派生クラスはプリミティブごとにあるということを説明しましたが、実際にはどんな感じなんでしょうか。Buffer クラス群のクラス図を図 1 に示します。 Buffer クラスは派生クラスとして、ByteBuffer などのプリミティブ型に対応した Buffer クラスが用意されているのが分かると思います。図 1 の青で表したクラスがそれです。また、メモリにマップしたファイルを扱うための MappedByteBuffer クラスがあります。 ところが、これらのクラスはすべて abstract クラスになっています。というのも、Buffer クラスの実装にはヒープを使用して行う実装と、ヒープの外に作る方法の 2 種類があるからです。最も基本的な byte 型に関してだけ実装クラスを示しました。図中では赤で示されているクラスです。これらのクラスはプライベートなクラスになっています。 ヒープを利用して Buffer を実装しているのが HeapByteBuffer クラスです。その派生クラスである HeapByteBufferR クラスは書き込みが禁止されているリードオンリーのクラスです。 ヒープ外のメモリにアクセスするのが DirectByteBuffer クラスです。同じようにリードオンリーの DirectByteBufferR クラスも用意されています。 クラス構成も分かったので、次からは Buffer クラスの使い方を調べていきましょう。
|
| 位置について | ||||||||||||||||||||||||||||||||||
|
使い方を調べるにあたって、いくつかのステップに分けましょう。
さっそく、Buffer クラスからいきましょう。 Buffer クラスには前述したように、要素にアクセスするためのメソッドは定義されていません。それでは、何が Buffer クラスに残されているのでしょうか。その答えは、位置です。 と、いわれてもさっぱり分からないですよね。Buffer クラスでは基本的に要素に対してシーケンシャルなアクセスを行います。このため、どこまでアクセスしたかを示すための位置 position を常に保持しています。 この position 以外にも、Buffer オブジェクトのコンテナのサイズを保持する capacity、position の限界値を示す limit があります。もう 1 つ、それほど使わないとは思いますが、position の記憶させておくための mark というのもあります。この 4 つのプロパティに関する操作が Buffer クラスには用意されています。
これら 4 つのプロパティには次のような式が常に成り立ちます。 0 <= mark <= position <= limit <= capacity ただし、mark は常にあるとは限りません。明示的に設定を行わない限り mark の値はないのです。 例をあげてみましょう。capacity が 15 の Buffer オブジェクトは次のようになります。 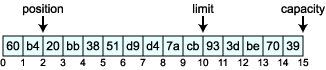 矢印で際しているところが各プロパティの位置なので、この Buffer オブジェクトのプロパティは
になっています。 それでは、さっそくサンプルでこれらのプロパティを操作してみましょう。
BufferTest1.java がメインになるのですが、Buffer オブジェクトの表示などを行うユーティリティクラス ByteBufferUtility.java も作りました。今回はすべてのサンプルでこのクラスを使用します。ここでは、特に ByteBufferUtility クラスの説明はしません。このドキュメントをある程度読んでいただければ、ByteBufferUtility クラスもすぐに理解できると思います。 それでは、BufferTest1 クラスの説明をしていきましょう。 BufferTest1 クラスでは ByteBuffer オブジェクトを使用して、position などのプロパティを操作しています。これらの操作は Buffer クラスで定義してあるものなので、ByteBuffer クラス以外のクラスを使用しても OK です。 Buffer オブジェクトの生成には allocate メソッドを使用します。引数は Buffer オブジェクトのサイズです。
allocate メソッドは static なメソッドなので、オブジェクトがなくてもコールすることができます。ただし、このメソッドは Buffer クラスで定義されていないので、使用したい派生クラスの allocate メソッドを使用するようにします。ここでは、サイズが 15 の ByteBuffer オブジェクトを生成しています。 次の行で生成した Buffer オブジェクトに適当に値を代入しています。また、その次の行でこの Buffer オブジェクトの表示を行っています。 ここまでの部分を実行したときにはこんな感じになります。
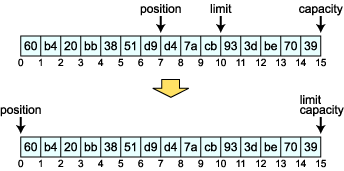
P, L, C はそれぞれ position, limit, capacity の位置を表しています。初期状態では position = 0, limit = 15, capacity = 15 になっています。 [ ] で囲まれているのが、Buffer オブジェクトが保持している要素になります。 次に、position を動かしてみましょう。これには position メソッドを使用します。int の引数がある場合は position をその位置に移動させ、引数無しの場合は現在の position の位置を返します。
結果は
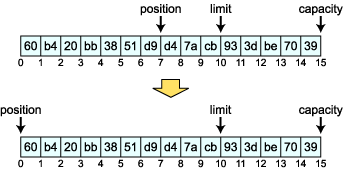
limit を移動させるには、limit メソッドを使います。position メソッドと同様に、引数ありで位置の設定、引数無しで limit の位置を返します。
出力を次に示します。
capacity は不変なので、これを設定することはできません。ただし、capacity メソッドはあって、引数無しで capacity を返します。 ところで、position, limit, capacity の関係は上述したように position <= limit <= capacity ですが、これが守られなかったらどうなるでしょう。さっそく、やってみましょう。
出力結果は
まぁ、あたりまえですが例外 (IllegalArgumentException) が発生しました。IllegalArgumentException は Runtime Exception なので、catch を行う必要はないのですが、例外が発生した後に position がどうなっているかを調べるために catch をしてみましょう。
例外が起きても、position の位置は変わりませんでした。 同様に limit を position 以下にしたり、position, limit を capacity 以上にした場合にも IllegalArgumentException が発生します。 position メソッドなど以外にも、postion などを操作することができます。次のサンプルではそのような操作をまとめてみました。
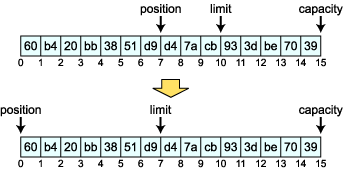
Clear 始めに登場するのは clear です。clear は position, limit を初期状態に戻します。つまり、postion = 0, limit = capacity に成ります。ただし、保持している要素は一切変更はありません。
Rewind rewind は position だけを 0 に移動させます。 position(0) と同じ結果になります。
Flip flip は position と limit を入れ替えるのですが、position は limit より大きくなることはないので、実際には limit を position の位置にして、position は 0 になります。
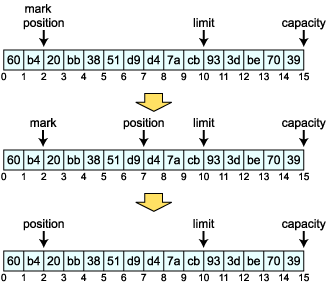
Mark & Reset 最後が mark と reset です。プロパティの mark はこのときだけ使用されます。 mark メソッドは現在の postion の位置を記憶しておきます。そして、その後 position が移動したときに reset メソッドをコールすると、mark したところに position が移動します。
|
|
要素へのアクセス 読み込み編 |
||||||||||||||||||||||||||||||||||
|
次のステップはプリミティブに特化した派生クラスに共通の機能の使い方ということで、要素へのアクセスを試みましょう。 要素へのアクセスには 2 種類の方法があります。
相対・絶対アクセスとも読み込みは get メソッドを使用します。相対・絶対の区別はメソッドの引数によって決まります。例として ByteBuffer クラスのメソッドを示しますが、他のクラスでも引数や戻り値の型が異なるだけで、使い方は同じです。
さっそく、サンプルで見ていきましょう。
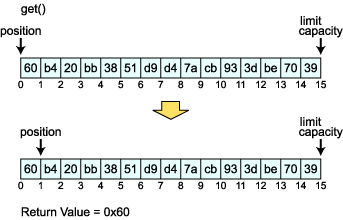
始めは単純な get() メソッドからです。get メソッドをコールすると position が 1 つ進みます。
get(byte[] dst) メソッドは dst のサイズだけ読み込みを行います。position もサイズ分移動します。
次の get(byte[] dst, int offset, int length) メソッドはちょっと癖があります。この動作は次に示すコードと同様の結果になります。
length バイト読み込むのですが、それを dst の始めから格納するのではなく offset 分だけずれて入れていくようになります。
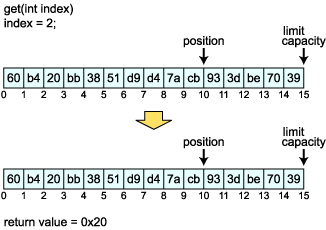
最後に残ったのが絶対アクセスを行う get(int index) メソッドです。このメソッドでは position は移動しません。
ここまでは普通に get メソッドを使用してきましたが、position = limit の時に get メソッドを使うとどうなるでしょうか。2 つの場合をやってみました。
これを実行してみると 次のように BufferUnderflowExcepton が発生しました。例外が発生するのはあたりまえですね ^^;; ただし、このときに position などの変化はありませんでした。
|
|
要素へのアクセス 書き込み編 |
|||||||||||||||||||||||||||||||||||
|
Buffer オブジェクトへの書き込みには put メソッドを使用します。これにも相対/絶対アクセスの両方があり、引数によって決まります。やはり ByteBuffer クラスのメソッド一覧を示しておきます。
get メソッドと対応させれば大体使い方はお分かりになると思います。
put(byte b) メソッドは 1 つの要素を position の位置に書き込みます。メソッドをコールすると position が 1 つ進みます。
put(byte[] src) メソッドは src を書き込みます。書き込む要素は src のサイズと同じです。position も書き込みを行った分だけ移動します。
offset と length を指定できる put(byte[] src, int offset, int length) メソッドも get メソッドと同様にちょっと癖があります。この動作は次に示すコードと同様の結果になります。
length バイト書き込みますが、dst[0] からではなく dst[offset] から書き込んでいきます。
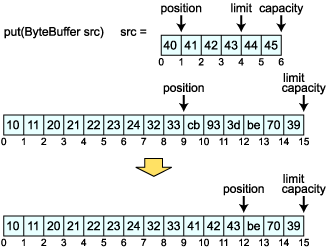
put(ByteBuffer src) メソッドは src を Buffer オブジェクトにコピーされます。このとき src の position から limit までがコピーされます。
このソースの中で srcBuffer に要素を書き込むときに put メソッドを連ねて行っています。これは put メソッドの戻り値が ByteBuffer であることを利用しているのですが、使うのはほどほどにしておかないと分かりにくいソースになってしまうので気をつけましょう。 さて、実行してみます。
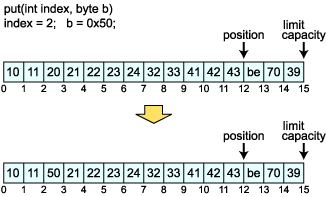
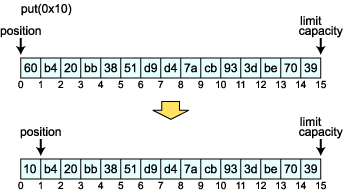
最後は絶対アクセスの put(int index, byte b) メソッドです。このメソッドではやはり position は移動しません。
get メソッドと同様にエラーになるような場合を確かめて見ましょう。
これを実行すると get メソッドとはことなり BufferOverflowExcepton が発生します。やはり、position などに変化はありませんでした。
|
|
byte から他の型へ |
|||||||||||
|
ByteBuffer クラスの読み書きを説明してきましたが、これは他の IntBuffer クラスでも同じように行うことができます。 でも、はじめから IntBuffer クラスを allocate していればいいのですが、ストリームなどからバイト列を読みこみ、それを int の値として使用するなどというときは困ってしまいます。ようするに、はじめにバイト列ありきのときにどうするかですね。 普通は byte から int に変換するのは、4 byte を読み込み、それを組み合わせて int を作ります。例えば、こんな感じです。
これはこれでいいのですが、いちいちこんなことをやるのも面倒ですね。と思って ByteBuffer の JavaDoc を見ていたら、ありました型の変換を行うメソッドが。 さっそく使ってみましょう。ということで、サンプルはこちら。
まずは、ByteBuffer から int の値を読み書きしてみましょう。
int の読み込みは getInt メソッド、書き込みは putInt メソッドを使用します。両者とも position の位置から 4 byte を読み/書きします。getInt メソッド、putInt メソッドはここで使った以外に絶対アクセス用のものも用意されています。 また、int 以外の読み書きを行うメソッドも getXXX/putXXX (XXX の部分に型が入る) が用意されています。 さて実行してみると、
電卓で計算してみると確かに 0x60b420bb は 1622417595 でした ^^;; また、putInt も確かに 0x0a が書き込まれているのが確認できます。 要素を 1 つ 1 つ読み書きするのはこれでいいのですが、まとめて全部 int にしたいというときには Buffer オブジェクトごと変換するメソッドが ByteBuffer クラスに用意されています。
asXXXBuffer メソッドは ByteBuffer を XXXBuffer (XXX には型の名前) に変換します。上の例だと asIntBuffer メソッドを使って IntBuffer オブジェクトに変換しています。このとき、position から limit の間の要素が変換対象となります。
position = 8 だったので、IntBuffer にすると残りの [7a, cb, 93, be, 70, 39] が IntBuffer オブジェクトへの対象となります。これが int のバイト数 4 で割り切れればいいのですが、割り切れないときは 4 に満たない部分が切り捨てられてしまいます。 最終的に [7a, cb, 98, be] が残って、1 つの要素をもつ IntBuffer オブジェクトができます。値を見るとちゃんと 0x7acb933d になっていることが分かるとおもいます。 さて、ここまできて気になることを思いつきました。それは Endian です。 Big Endian と Little Endian では同じ int の値でも、バイト列としてみると異なります。今までの例を見ていると、どうやら Big Endian になっているようですが、Little Endian でも扱うことができるのでしょうか。 答えは可能です。 New I/O では ByteOrder クラスという Endian を表すためのクラスが導入されています。これを使用して、ByteBuffer オブジェクトの Endian を指定することができます。 ただし、デフォルトの Endian は先ほどの例で示したように Big Endian になっています。
ByteBuffer クラスの order メソッドは、引数なしだと Endian を返し、ByteOrder オブジェクトを引数にすると Endian を変更します。ByteOrder クラスは 2 つの定数オブジェクトが用意されています。それぞれは ByteOrder.BIG_ENDIAN と ByteOrder.LITTLE_ENDIAN になります。 さて、実行してみましょう。
Little Endian にしても、ByteBuffer オブジェクト自体のデータの並びは変更されません。でも、getInt メソッドした値は Little Endian で読み込まれたことが確認できます。
|
|
Buffer オブジェクトの操作 |
||||||||||||||||||||||||||
|
まだ、説明していない残された機能があります。この章ではそれらの機能を説明していきます。ただし、ここで説明する機能は Buffer クラスでは定義されておらず、派生クラスで定義されています。 Buffer オブジェクトの操作には次のようなものがあります。
説明だけだとよく分からないので、サンプルを使って確かめていきましょう。
Compact はじめは compact メソッドからです。compact メソッドを実行すると position と limit の間にある [51, d9, d4, 7a, cb, 93, 3d] がBuffer オブジェクトの先頭にコピーされています。また、position の位置はコピーされた最後の要素の後になり、limit は capacity と同じになります。
さっそく、実行。
comapct メソッドは直接 Buffer オブジェクトに行うので compact メソッドの戻り値の Buffer オブジェクトはもともとの Buffer オブジェクトと同一のものになります。 Duplicate 次は簡単です。duplicate メソッドは Buffer オブジェクトのコピーを作ります。
実行してみると、コピーが作られているのが確認できます。
ただし、コピーといっても、Buffer オブジェクトが保持している要素自体のコピーは行いません。position, limit, capacity はコピーされて、元の Buffer オブジェクトのそれとは別になります。 例えば、duplicate メソッドを使用してコピーした Buffer オブジェクトに書き込みを行ってみました。
コピーを行った後に、position を 0 にし、0x10 を書き込んでいます。これを実行してみると、
元の Buffer オブジェクトも、コピーした Buffer オブジェクトも要素が変化しているのがお分かりだと思います。ただし、position の値は両者で異なっています。 このようなコピーのことを shallow copy といいます。これに対して、要素まですべてコピーするようなコピーを deep copy といいます。 Java ではオブジェクトのコピーを行うときなどは一般的に shallow copy になります。例えば、Object クラスの clone メソッドは shallow copy を行います。 Slice slice メソッドは Buffer オブジェクトの一部を切り出して、新たに Buffer オブジェクトを生成します。
position と limit の間の要素 [d4, 7a, cb, 93, 3d] だけを切り出して、新たに Buffer オブジェクトを作ります。
slice メソッドを使用しても、もとの Buffer オブジェクトは変更されません。slice メソッドの戻り値の Buffer オブジェクトとは異なるオブジェクトになります。 Wrap wrap メソッドは byte 配列から ByteBuffer オブジェクトを生成するためのメソッドで static メソッドになります。他のクラスも対応するプリミティブの配列からそのクラスのオブジェクトを生成する wrap メソッドを持ちます。
wrap メソッドには offset と length を指定できるものもありますが、ここでは単純に byte 配列を引数にするものを使ってみました。
allocate メソッドは初期値を渡せないのですが、wrap メソッドを使用すれば初期値のある Buffer オブジェクトを生成することができます。
|
|
ヒープの外に |
||||||||
|
まだ、説明していない機能にメモリにマップされたファイルへのアクセスと Java のヒープ外のメモリへの直接アクセスがあります。しかし、メモリマップファイルは Channel と一緒に説明したほうがいいので今回はやりません。 したがって、最後はヒープ外のメモリのアクセスです。 ヒープ外のメモリをアクセスするといっても、結局は Buffer オブジェクトの要素をヒープの外に作るということです。その Buffer オブジェクを使用して、要素にアクセスすればヒープ外のメモリにアクセスすることになります。 ヒープの外に作るというのは C や C++ の配列と同じになります。Java の配列は、配列といっても実際には配列クラスのオブジェクトになっています。 この配列のクラスは終端の処理などをやってくれたりするので、使う側にとってはいろいろと利点があります。しかし、この処理をしているために、C/C++ の配列に比較すると処理速度が若干落ちてしまうという欠点があります。 そこで、Buffer クラスではヒープの外に C や C++ で作った配列をおき、それをアクセスすることができます。このような Buffer オブジェクトは通常の allocate メソッドを使用して生成するのではなく、allocateDirect メソッドを使用して生成します。 ただし、allocateDirect メソッドは ByteBuffer クラスにしか定義されていません。 allocateDirect メソッドで生成してしまえば、使い方は通常の Buffer オブジェクトと同じです。とはいっても、allocateDirect メソッドで生成した Buffer オブジェクトが GC されなければ、ヒープ外にメモリをアロケートしたままになってしまい、下手をするとメモリリークを引き起こしたりします。ですから、使うときには細心の注意を払ってください。 さて、allocateDirect で生成した Buffer オブジェクトと普通の Buffer オブジェクトの違いはなんといってもパフォーマンスです。簡単なプログラムでどれくらいパフォーマンスが違うか試してみましょう。
BufferTest7 クラスでは capacity の同じ Buffer オブジェクトを 2 つ生成しています。一方が allocate メソッド、もう一方が allocateDirect メソッドを使用しています。
この 2 つのオブジェクトに対して、先頭からすべての要素を get するという比較をしてみました。比較する部分は次のようにしています。
さっそく実行してみたいのですが、Buffer オブジェクトの capacity があまりにも大きいので普通に実行すると OutOfMemoryError が発生してしまいます。そこで、-Xmx オプションを使用して最大メモリを指定することにしました。-Xmx のデフォルト値は 64MB なので、それ以上の 256MB などで実行してみてください。
筆者の環境は CPU が Athlon 800MHz, Memory 512MB で、Windows 2000 上で実行させてみました。単なる get メソッドを用いた読み込みだけでも 1 秒以上の差があります。有効に使えば、パフォーマンスがかなり向上するのではないでしょうか。 実行すると、 2 種類の Buffer オブジェクトの情報を出力しています。この部分の実装は次のようになっています。単にオブジェクトを println メソッドを使用して書き出しているだけです。
この出力結果を見ると、allocate メソッドで生成されたバッファは HeapByteBuffer クラス、allocateDirect メソッドでは DirectByteBuffer クラスになっています。図 1 に示したようにどちらも ByteBuffer クラスの派生クラスになっています (DirectByteBuffer クラスは ByteBuffer クラスの孫クラスですが)。このため、両者とも ByteBuffer オブジェクトとして使うことはできますが、要素のアロケートの実装方法によりクラスを分けているということが分かります。 この 2 つのクラスは public なクラスではないので、JavaDoc には記載されていません。というのも、ユーザにとっては使い方が同じであれば、実装方法は気にしないでいいからだと思います。オブジェクト指向のカプセル化の例の 1 つになっているのではないでしょうか。 ところで、先ほど allocateDirect メソッドは ByteBuffer クラスにしかないと説明しましたが、IntBuffer クラスでも Direct な Buffer オブジェクトを使いたいと思うことはあると思います。さて、どうしましょう。 答えは簡単で allocateDirect メソッドで生成した ByteBuffer オブジェクトを asIntBuffer メソッドを使用して IntBuffer オブジェクトに変換すればいいのです。この方法で他の Buffer クラスの派生クラスでも Direct なオブジェクトを使用することができます。
|
|
最後に |
||
|
配列とも Collection とも違う Buffer クラスでが、なかなか使いでがありそうです。プリミティブに関しては今まで Collection を使いたくても使えないので、配列しか選択の余地はなかったのですが、Buffer クラスが加わったことで選択の範囲が広がりました。 Buffer クラスを使うと配列にはないいろいろな特徴があるので、これらを有効に使っていきたいですね。 特に Channel などの他の New I/O で導入されたクラスと一緒に使うと効果が大きいようです。JavaOne 2001 ではグランドキャニオンの CG のデモが公開されました。これは以下の Web Page で公開されています。 Grand
Canyon Demo Page このデモでは約 100MB のデータを Channel と Buffer を使用して読み込んでいるようです。実際に実行して New I/O を使ったときと使わないときの差を肌で感じてみてください。 今回使用したサンプルはここからダウンロードできます。 参考 URL
(Sep. 2001)
|
|
|
![Buffer get(byte[] dst)](img/bufferget2.gif)
![Buffer get(byte[] dst, int offset, int length)](img/bufferget3.gif)
![Buffer put(byte[] src)](img/bufferput2.gif)
![Buffer put(byte[] src, int offset, int length)](img/bufferput3.gif)