|
|
Concurrency Utilities その一 非同期処理の巻 |
||||
|
||||
| マルチスレッドのアプリケーションはいろいろ時をつけなくてはいけないことがあります。同期や同時アクセスやプライオリティ、デッドロックなどなど。 Java では安易にスレッドを作ることができるのでいつのまにかスレッドをたくさん使っていたなんてことも起こりがちですが、そのつけは大きいです。 そんなマルチスレッドのアプリケーションを作る際に福音書となっているのが Java スレッドプログラミング です。残念ながら今は品切れで入手が困難なので、もし本屋に残ってたらすぐにでも購入したほうがいいです。 マルチスレッドと同様この本も内容が難しくて、なかなか理解するのが大変なんですが、マスターできたら鬼に金棒状態です。そして、この本の作者が Concurrency Utilities の原型を作った Doug Lea なのです。 Concurrency Utilities では次のような機能を提供しています。
その他に Thread クラスの変更なども含まれています。 結構なボリュームがあるので、とりあえずここでは非同期実行、スレッドプールを取り上げたいと思っています。残りの項目に関しては その 2 以降で。
|
|
|||||
| 普段、プログラミングをしていても、同期だとか非同期とかはあまり気にすることはありません。というのも、ほとんど同期処理しか行わないからです。 ようするにメソッドをコールしたら、そのメソッドの処理が終わるまで待たなくてはいけないということです。 逆にいえば、非同期処理は珍しいのです。その珍しい例をあげてみると
ぐらいしか思いつきません ^^;; SwingUtilities#invokeLater メソッドは普段最も使われる非同期処理ではないでしょうか。たとえば、ボタンが押されたときにあまり時間がかかる処理の場合、そこでウンスンになってしまうので後で行わせるというものです。でも、実際にはこれは純粋な非同期処理ではありません。というのも、結局処理するスレッドは同じだからです。 次のようなプログラムだとボタンが押されたら、ボタンが押された状態のままになってしまいます。これは結局 Swing のイベントスレッドが invokeLater メソッドで指定された処理も行ってしまうからです (本当の理由はもうちょっと複雑ですが...)。
非同期処理を書かなくてはいけないとしたらどう書くか考えて見ましょう。 普通は Runnable インタフェースを使って、別のスレッドで処理を行わせます。
別スレッドで行わせている処理が終わったかどうかを調べるためにはイベントを使ったり、wait ... notify を使ったりします。たとえば、wait ... notify を使うとすると次のようになります。
wait ... notify を使うと synchronized にしたり、いろいろ面倒くさそうです。 その面倒くさいところをやってくれるのが Concurrency Utilities なのです。
|
|
|||||||||||||
| 非同期処理を行うためにキーとなるのが java.util.concurrent.Executor インタフェースです。後から Executor を派生させた ExecutorService というインタフェースも出てきますが、それは後の話。 Executor インタフェースには次のメソッドが定義されています。単にこれだけです。
Executor インタフェースの JavaDoc にはこのインタフェースをインプリメントしたクラスのサンプルが出ています。一番簡単なのが次に示す DirectExecutor クラスです。
Runnable インタフェースの run メソッドをコールしているだけです。Thread#start メソッドではなくて、Runnable#run メソッドです。 これを使って簡単なサンプルを作ってみました。
何回か出てくる ConcurrentUtils#listThread メソッドはスレッドの一覧を表示するために作ったメソッドで次のような実装になっています。
ThreadGroup クラスには、自分が管理しているスレッドグループおよびスレッドの一覧を表示する list メソッドがあります。これを利用しています。 さて、ExecutorTest1 を実行してみましょう。
あれっと思いませんか。というのもスレッド数はプログラムを通して全然変わっていないからです。 このプログラムは実をいうと非同期でもなんでもありません。executor メソッドを呼び出しても、単に run メソッドを呼ぶだけなので同期で実行します。 これじゃyおもしろくないですね。 どうやら、マルチスレッドで非同期処理を行うには、Executor が自分でスレッドを用意しなくてはいけないようです。 そこで、やはり Executor インタフェースの JavaDoc にのっている ThreadPerTaskExecutor クラスを使ってみました。
execute メソッドがコールされると、毎回スレッドを作って処理を実行させます。 この Executor を使って先ほどの ExecutorTest1 クラスを書きかえたのが、ExecutorTest1_1 クラスです。
これを実行してみましょう。
これだと RunnableTask#run メソッドは ThreadPerTaskExecutor スレッドで行われていることが分かります。 でも、毎回スレッドを作るのも嫌な感じです。次章ではそこいらへんを考えてみましょう。
|
|
|||||||||||||
| タスクがあるごとにスレッドを作っていたら、毎回生成するのも時間がかかりますし、スレッドの管理をするにもやりにくくなって、いいことはあまりありません。 毎回スレッドを作るのがよくないならば、使いまわせばいいですね。この方式をスレッドプールといいます。 スレッドを常に用意しておいて、必要なときにプールしておいたスレッドを使用するわけです。使い終わったスレッドはまた次のタスクが登録されるまで遊ばせておきます。 今までスレッドプールを作るのはそれなりに面倒くさかったのですが、Concurrency Utilities にはスレッドプールをすぐに使えるようなメソッドが用意されています。 Executors クラスで定義されている
がスレッドプールを生成するためのメソッドになります。この他にも newSingleThreadScheduledExecutor という長い名前のスレッドプールを作成するメソッドもあります。 いずれのメソッドも static なので、いつでもどこでもスレッドプールを生成することができます。 これらの中で一番簡単な newSingleThreadExecutor メソッドを使用して、先ほどの ExecutorTest1 クラスを書きかえてみましょう。
先ほどと違うのは、Executor オブジェクトを生成する部分だけです。
これで、自分で Executor インタフェースの実装クラスを書く必要はありません。 さて、実行してみましょう。タスクを実行しているスレッドが pool-1-thread-1 と表示されているのがお分かりでしょうか。
うまくいったと思ったのもつかの間、このサンプルは終わらないのです。 どうやら、新たなタスクが登録されるのを待っている状態にあるらしいです。しかし、それを制御するためのメソッドは Executor インタフェースにはありません。困った。 こういうときはやっぱり Javadoc。もういちど、newSingleThreadExecutor メソッドを見てみました。 そうしたら、newSingleThreadExecutor メソッドの戻り値は Executor オブジェクトではないことに気がつきました。ExecutorService インタフェースになっています。ExecutorService インタフェースはスレッドプールなどに対応した Executor インタフェースの派生インタフェースとなっているようです。 そこで、ExecutorService インタフェースの Javadoc を見てみます。そうしたら、ありました。shutdown メソッドと shutdownNow メソッドです。この両者ともシャットダウンの処理は同じようですが、登録だけされてまだ実行していないタスクを戻り値として返すかどうかの違いのようです。 このメソッドを main メソッドの最後に入れたものが ExecutorTest2_1 クラスです。
実行してみると、ちゃんと終了するのが確認できると思います。
shutdown メソッドをコールしてからスレッドの一覧を表示しているのですが、pool-1-thread-1 スレッドがなくなっているのが確認できます。 さて、ExecutorService オブジェクトを生成させたメソッド newSingleThreadExecutor メソッドは名前のとおり、1 つのスレッドでタスクを処理するはずです。 それを確かめるために複数のタスクを処理させてます。
単に RunnableTask オブジェクトを複数生成して、execute メソッドをコールしているだけです。
これを実行してみます。関係のある部分だけ下に示しました。
シングルスレッドなので、タスクが同時に処理されることはないはずです。上の例でも execute メソッドは、前の処理が終わる前にコールしているのですが、前のタスクの終了後に処理されていることが分かります。 また、どちらのタスクも pool-1-thread-1 スレッドで実行されていることも分かります。
|
|
||||||||||||||||||||||||||
| newSingleThreadExecutor メソッド以外のメソッドで生成されるスレッドプールはちょっと置いておいて、先に ExecutorService インタフェースをもう少し詳しく見ていきましょう。 そうすると、execute メソッド以外に submit メソッドというのがあることが分かります。しかし、処理内容は execute メソッドと何が違うのでしょう。 答えは戻り値を戻すかどうかということにあります。sumbit メソッドの戻り値は Future オブジェクトです。 java.util.concurrent.Future インタフェースの Javadoc を見てみると、登録されたタスクがどのような状態にあるかなどを調べることができるインタフェースのようです。 isDone メソッドでタスクが終了しているかどうか、isCancelled メソッドがタスクがキャンセルされたかを示すようです。また、cancel メソッドでタスクをキャンセルすることもできるようです。 これらのメソッドの意味は分かるのですが、分からないのが get メソッドです。結果を取得できるというのですが... 何の結果なのでしょう? まぁ、難しいことは考えずに、使ってみましょう。
このサンプルでは isDone メソッドでタスクが終了しているかどうかを調べてみました。 また、何の結果だがよく分かりませんが、とりあえず get メソッドをコールしてみます。
実行してみると、まず
と表示されます。そして、しばらくすると
と表示されます。 get メソッドをコールする前にスリープなのは入れていないのですが、get メソッドでブロックしているようです。 Javadoc を読んでみると、get メソッドはタスクが処理するまでブロックすると書いてあります。今ままでのサンプルはタスクがいつ終わるか分からなかったので、適当にスリープを入れておいたのですが、get メソッドを入れておけばタスクの終了を知ることが出来るようです。 また、タスクが終了したら isDone メソッドの戻り値が true になるので、これでタスクが終了したかどうかも調べることが可能になります。 しかし、get メソッドの戻り値は null。結局、何の結果だかよく分からないままです ^^;; 分からないことは先延ばしして、Future#cancel メソッドを使ってみます。
submit メソッドの戻り値の Future オブジェクトに対して cancel メソッドをコールしているだけです。
実行して見ます。
スタックトレースと普通の出力が交じってしまって見にくいですが、InterruptedException が発生していることはよく分かると思います。すなわち、cancel メソッドがスレッドの interrupt を呼び出しているわけです。 ということは、InterruptedException を正しく処理していない場合や、InterruptedException が発生しないような処理では cancel メソッドをコールしても処理は止まらない可能性もあるということです。 Javadoc の cancel メソッドの説明にも This attempt will fail if the task has ... could not be cancelled for some other reason という記述があり、必ずしも cancel できるとは限らないようです。 さて、先延ばしにしていた get メソッドの戻り値についてもう一度調べてみます。やはり、困ったときはやはり Javadoc に戻りましょう。 ExecutorService インタフェースの submit メソッドを見てみると、引数に Runnable オブジェクトと任意の型 (Generics を利用しています) の result というメソッドがオーバロードされています。 result という引数の名前が怪しいですね。 そこで、ExecutorTest3 を、このオーバロードされた submit メソッドに変更してみました。
result には単純に true を入れています。
実行したらどうなると思いますか。
おぉ、ちゃんと true が戻ってきました。これで、タスク処理が終わったかどうかを判定させることができます。 けど、本当にそんな使い方のために submit メソッドがあるのでしょうか... ちがいます ^^;; submit メソッドにはもう 1 つオーバロードがあります。それは Callable オブジェクトを引数にとるものです。 この Callable インタフェースというのは何なんでしょう? 2003 年の JavaOne で Doug Lea はこの 2 つのインタフェースの違いを次のように書いています。
よく分かりません ^^;; それでも、Callable インタフェースのソースを見ると違いがわかります。Callable インタフェースは次のように定義されています。
メソッド名が run ではなくて call ということよりも大きい違いがあります。 それは Callable#call メソッドには戻り値があるということです。 Runnable#run メソッドには戻り値がないので、非同期処理の結果を受け取るにはそれなりの工夫が必要です。それに対して Callable#call メソッドは戻り値があるので非同期処理の結果を戻すのが簡単だという違いがあるのです。 ということは、Future#get メソッドの戻り値の結果というのは call メソッドの戻り値と仮定することができます。 さっそく、サンプルを作ってこれを確かめてみましょう。
call メソッドは、現在時刻を返すようにしてみました。
実行するとどうなるでしょうか。
どうやら仮説はあっていたようです。ちゃんと call メソッドの戻り値を get メソッドで取得することができました。 今まで、非同期処理は Runnable インタフェースしかなかったので、処理の結果を戻すためにはクラスフィールドにするなどの工夫が必要でした。 しかい、Callable インタフェースを使えば、そういう面倒くさいことを考えずに、非同期処理の結果を扱うことができるようになります。 この違いが Doug Lea のいうところの Actions と Functions なんでしょうね。
|
|
|||||||||||
| Runnable インタフェースと Callable インタフェースの違いが分かったので、ExecutorService インタフェースに話を戻しましょう。 ExecutorService インタフェースの Javadoc を見ていると invokeAll と invokeAny という何やら怪しげなメソッドがあります。これらのメソッドを使ってみましょう。
invokeAll メソッドは引数が Callable インタフェースのコレクションになっているので、登録したタスクをすべて実行するのでしょう。
CallableTask クラスは次のように単にスリープして自分の名前を返すようにしています。
Executors#newSingleThreadExecutor メソッドでスレッドプールを取得しているので、シーケンシャルに実行されることが予想されますが、どうでしょう。
invokeAll メソッドですべてのタスクが実行されることが分かります。しかもシーケンシャルに実行されていることも分かるのですが、すべての処理が終わらないと Future#get メソッドから戻らないというのもおもしろいですね。そんなもんなのでしょうか。 次は、もう 1 つの invokeAny メソッドです。
invokeAny の Any というのはどういう意味なのでしょうか。All だったらすべてですが... しかも、invokeAny メソッドの戻り値はコレクションではなく Callable#call の戻り値になっています。
CallableTask クラスは先ほどと同じにしています。
Any なので、1 しか実行されないのかと思ったのですが、どうやら違ったようです。とりあえず処理できるだけ処理させておいて、処理結果が戻ってきたらその時点で終わりにしているようです。 これはどういうときに使うのでしょうね? よく分かりません。
|
|
||||||||||||||||||||||||||||||||||||||
| 今までは Executors#newSingleThreadExecutor メソッドを使用して ExecutorService オブジェクトを取得していたのでシングルスレッドでシーケンシャルにタスクを処理していました。でも、これじゃあまりスレッドプールっぽくないですね。 その他の newFixedThreadPool メソッドや newCachedThreadPool メソッドを使って、普通のスレッドプールを体験してみます。 スレッドプールの実現には 2 種類の方法が考えられます。
1 の方法は Executors#newFixedThreadPool メソッド、2 の方法は Executors#newCachedThreadPool メソッドが対応しています。
はじめは Executors#newFixedThreadPool メソッドを使用してみます。
Fixed なのでスレッドの上限が決まってはずです。その時々のスレッドを見ていればそれが確認できます。
はじめはタスク処理用のスレッドがなかったのが、タスクを登録するたびに増えていく様子が分かるでしょうか。 Task 0 は pool-1-thread-1 で処理され、Task 1 は pool-2-thread-2 で処理されています。 タスクがスレッドの上限を超えてしまったらどうなるでしょうか。
次のように 5 つのタスクを登録してみました。上限は 3 なのでどうなるでしょうか。
結果は予想できますね。
予想通りスレッドは 3 しか作られませんでした。一度に処理のできないタスクは待ち状態にあり、実行中のタスクが終了すると、次の待ち状態にあるタスクの処理がはじまっています。 次は Executors#newCachedThreadPool メソッドでスレッドプールを作ってみましょう。
以下のコードのようにどんどんタスクを投入してみます。
たぶん、 5 つタスクを登録すれば、5 つのスレッドができると思うのですが...
予想通り 5 つのスレッドがパラレルに走って、タスクを処理しています。 しかし、このようにタスクを登録していったらどんどんスレッドが増えていってしまうのでしょうか。
ほぼ同時にタスクを登録するのがいけないのであって、すこし間隔をあけてタスクを登録してみます。
こうすれば、最後の方にタスクを登録するときには、はじめの方のタスクは終了しているはずなので、スレッドが使いまわされるはずです。
予想通り、2 つのスレッドだけでタスク処理が行われました。 ところで、これらのスレッドは使われなくなったらどうなるのでしょうか。実をいうと newFixedThreadPool メソッドも newCachedThreadPool メソッドも同じクラスのオブジェクトを返すだけです。 Executors クラスの該当部分を抜き出してみます。
この java.util.concurrent.ThreadPoolExecutor クラスのコンストラクタは
なので、スレッドが生き抜くのは第 3 引数で指定される時間になります。 newFixedThreadPool メソッドの場合ははじめから指定されたスレッドを作成し、それが増減することはありません。 newCachedThreadPool メソッドでは、初期状態では 0 個のスレッド、最大は int で表される最大値になります。また、60 秒間タスクがなければスレッドは消滅します。 これを試してみましょう。
タスクを登録してから 20 秒ごとにスレッドを表示してみます。
少し長いのですが実行結果を示します。
60 秒の時はまだワーキングスレッドが残っていますが、80 秒の時はなくなっています。 キープアライブ時間は 60 秒なのに 60 秒の時にスレッドが残っているのは変な感じを受けるかもしれません。しかし、よく考えてみるとタスクがなくなってから 60 秒なのです。タスク処理には 2 秒必要なので、60 秒の時にはまだ残っているわけですね。
|
|
|||||||||||||
| Executors クラスの Javadoc を見ているとまだスレッドプールを生成するためのメソッドがあることが分かります。 Executors#newSingleThreadScheduledExecutor メソッドとは Executors#newScheduledThreadPool は戻り値として ScheduledExecutorService オブジェクトを返します。 名前からして java.util.Timer クラスのような遅延処理や繰り返し処理を行うだろうということは予想できます。Timer クラスだとワーキングスレッドは 1 つなのですが ScheduledExecutorService インタフェースはスレッドプールに対応しているので複数のスレッドで繰り返し処理を行うことができそうです。 まずは遅延処理からです。
タスクを遅延処理するためには execute メソッドではなく schedule メソッドを使用します。schdule メソッドの第 1 引数は Runnable オブジェクトもしくは Callable オブジェクト、第 2 引数が遅延させる時間、第 3 引数が時間の単位です。
この例だと 2 秒後にタスクが処理されます。 ここで使用しているタスクも示しておきます。
単にコールされたときの時間を表示し、抜けるときにも時間を表示するというものです。
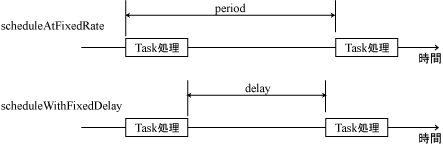
実行すると schedule メソッドがコールされたのが 23:01:17 なのに対して、実際に RunnableTask#run がコールされたのは 23:01:19 とちゃんと 2 秒後になっているのが分かります。 遅延はそれほど難しくはありません。 よく分からないのが繰り返し処理です。何がよく分からないかというと英語です ^^;; 繰り返し処理を行う場合、scheduleAtFixedRate メソッドと scheduleWithFixedDelay という 2 つのメソッドを使用します。 それにしても at XXX rate と with XXX delay の違いは何なのでしょう? 全然分かりません。こういうときに英語のネイティブな方はいいですよね。すぐ違いが分かるのですから。 まぁ、愚痴をいってもしょうがないので、とりあえずサンプル作って何が違うか見てみましょう。
1 秒間スリープするタスクを 2 秒周期で scheduleAtFixedRate メソッドと scheduleWithFixedDelay メソッドの両方を使用して登録してみました。
まずは scheduleAtFixedRate メソッドを使ったほうの実行結果です。
タスクは 2 秒後とに処理されていることが分かります。 次に scheduleWithFixedDelay メソッドを使ったほうです。
よく見てください。違いが分かりますか。 scheduleWithFixedDelay メソッドを使った場合、3 秒おきにタスクが処理されているのがお分かりでしょうか。 どうやら、この 2 つのメソッドの違いはタスク処理が開始する間隔とタスク処理間の間隔ということにありそうです。
このため scheduleAtFixedRate メソッドを使用すれば、タスク処理時間にかかわらず定期的に処理を行うことができます。しかし、タスク処理時間 > period の場合、処理は遅延してしまうようです。 逆にscheduleWithFixedDelay メソッドの場合、タスク処理にいくら時間がかかってもタスクとタスクの間の時間は変化しません。 このような性質の差があることがわかれば、使い分けもできそうです。
|
|
||||
| Executor インタフェースと Executors クラスを使えば、面倒くさい非同期処理やスレッドプールも思いのままです。いままでちょっと手を出しにくかった方も、これならば全然 OK ですね。 しかし、ちょっと不安も残ります。それは RuntimeException の問題です。非同期処理中に RuntimeException が発生すると、だれも catch できないのでスレッドが落ちてしまうという問題です。J2SE 1.4 までは ThreadGroup#uncaughtException メソッドを使用してだれも catch しなかった RuntimeException を捕らえることができました。 しかし、ThreadPoolExecutor クラスで生成されるスレッドはメインスレッドと同じスレッドグループなので、uncaughtException メソッドをオーバライドすることはできません。 どうすればいいか。答えは そのニ へ。
今回使用したサンプルはここからダウンロードできます。 参考
(Feb. 2004) |
|
|